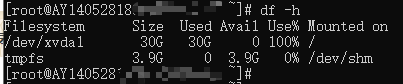
> 今天有个同事找我,说他前公司网站出了问题,访问报错Got error 28 from storage engine Error No:1030,问我是什么问题,余下省略一千个字。
说明:crontab命令 被用来提交和管理用户的需要周期性执行的任务,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
语法crontab(选项)(参数)选项-e:编辑该用户的计时器设置;
-l:列出该用户...
有的时候在某些场景中需要展示特定格式的图片,而在前端无法处理或者不方便处理时,我们只有使用PHP的GD库来解决了。这边解决的思路是:使用GD库生成网络或本地图片的替换文件到本地。<?php/**@desc 图片格式转换@param string $srcFile 原图片地址@param string...
python调用浏览器打开指定网站# -*- coding:utf-8 -*-
# 网站刷点击
import os
import re
import sys
import time
import random
import driver
import datetime
import requests
import threading
import w...
> 在爬取网页的时候我们经常会遇到乱码,但是我们可以通过查看网页的源代码查看charset方式。打开要访问的url,查看网页源码会发现类似代码:<meta charset="utf-8">,通常在代码中加入decode(‘utf8’)进行解码即可代码如下:(有时不需要编码即可默认输出了,所以不必多此一举)# -*-...